



Les indicateurs de performance clés (KPIs) contribuent à répondre aux objectifs de base du service d'assistance informatique tels que la continuité des activités, la productivité organisationnelle et la prestation des services dans les délais et le budget fixés. Cet article traite u KPI "la stabilité de l'infrastructure".
Définition: Une infrastructure très stable est caractérisée par une disponibilité maximale, très peu de pannes et des interruptions de service peu fréquentes.
Objectif: Maintenir une infrastructure très stable.
Pour mesurer et surveiller efficacement la stabilité de l'infrastructure, les HelpDesk informatiques doivent surveiller :
- Le pourcentage de réduction du nombre d'actifs posant probléme.
- Le pourcentage de réduction du nombre d'incidents majeurs.
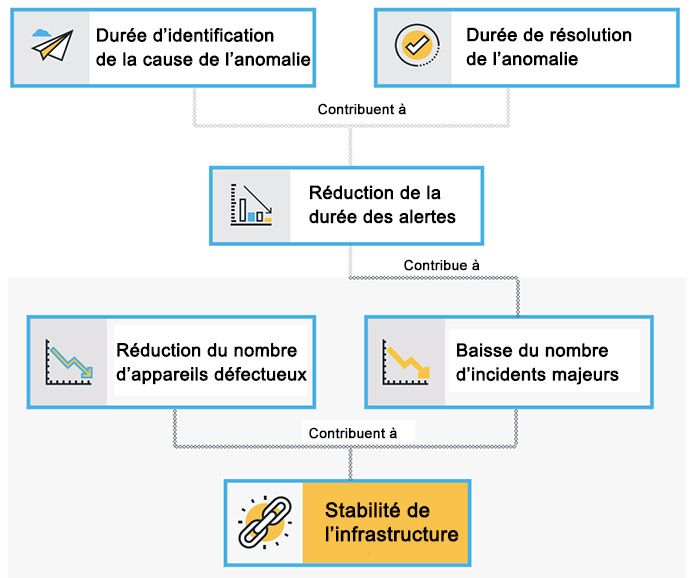
La stabilité de l'infrastructure : réduction du nombre d'actifs à problème
Fournir une disponibilité maximale et une meilleure qualité de service sera impossible dans une infrastructure où les routeurs doivent être redémarrés plusieurs fois par jour, où les serveurs sont souvent en panne, où les postes de travail doivent être redémarrés régulièrement. Par conséquent, ces actifs à problème doivent être identifiés et remplacés pour assurer la continuité des activités. Un actif problématique pourrait être la cause de plusieurs perturbations de service ou de pannes et pourrait être déjà associé à plusieurs incidents.
La stabilité de l'infrastructure : réduction du nombre d'incidents majeurs
Une autre indication importante concernant la stabilité de l’infrastructure est la récurrence des incidents majeurs sur l'infrastructure informatique qui peuvent conduire à des interruptions de service ou la détérioration du niveau de service. Un incident majeur, par définition, est un incident ayant un fort impact, qui nécessite des actions en urgence, qui affecte un grand nombre d'utilisateurs et qui prive l'entreprise d'un ou deux services clés.
L'objectif est de réduire le nombre d'incidents majeurs en faisant une analyse des causes (root cause analysis -RCA). Identifier les causes profondes et les problèmes permet de réduire la récurrence des incidents majeurs et, par la suite, le volume de tickets générés pour le service d'assistance informatique.
Conseils pour réduire les incidents majeurs
- Une initiation plus rapide des RCA : Dans ce cas, le plus tôt sera le mieux. Plus tôt le RCA sera initié, plus les chances d'identifier la cause du problème seront élevées.
- Un achèvement rapide des analyses : Si la cause est identifiée plus rapidement, l'équipe informatique pourra résoudre le problème plus rapidement et s’assurer qu’il ne se reproduira plus.
Les équipes peuvent également mesurer ces éléments en prenant en compte le temps pris pour lancer l'analyse des causes profondes suite à l'identification du problème ainsi que le temps nécessaire pour achever l'analyse.
Les principales difficultés pour résoudre un problème majeur sont dues à :
- Des RCA retardées et trop longues.
- Une mauvaise qualité des RCA et un manque de documentation appropriée.
- Une communication inefficace auprès des parties prenantes dans le processus d’analyse.
Sans identifier et corriger la cause d’un problème, les chances que des incidents majeurs apparaissent régulièrement sont assez élevées. Heureusement, ceci peut être réduit avec :
- Une équipe de gestion des problèmes dédiée avec des administrateurs et des gestionnaires de problèmes.
- Une identification et la formation d’experts en la matière.
- La formation de l'équipe de gestion des problèmes sur les techniques de base et avancées d'analyse des causes.
Travailler sur ces deux métriques - réduction du nombre d'incidents majeurs et de réduction des atifs à problème - peut vous aider à maintenir une infrastructure informatique très stable.